How Product Managers Should Think About User Analytics



The practice of making data-based decisions in software is nothing new. Understanding what your users are doing can inform decisions at all levels of your organization.
For example, it is not enough to calculate the click-through rate of your ads/campaigns. It is equally important to monitor the signup conversion rate of users who visit your site through each channel.
This makes it easier to allocate your marketing spend based on performance you actually care about (signups) as opposed to proxies (clicks).
Once people enter your product, tracking their actions becomes even more crucial. At the simplest level, it makes product managers’ lives easier since they don’t have to guess who has used a certain feature when seeking feedback.
Once you collect enough data, more advanced analysts can use logistic regressions to learn which actions in your product correlate with conversions to paid customers. That insight is as good as gold, because you can focus on driving users to those actions.
For example, Facebook found that users who added at least seven friends in the first 10 days were much more likely to become long-term active users. Once they figured that out, they focused all their efforts on making that happen for as many users as possible — and we all know how that turned out.
So, we’ve confirmed that collecting and analyzing user data will help product managers build better products. Let’s kick it up a notch and discuss some “gotcha” moments that can crop up:
1. Don’t Get Locked In
When designing your instrumentation infrastructure, it’s important to avoid boxing yourself in. You should aim to implement a flexible platform approach that makes it easy to add new kinds of tracking and send that tracking data to any tool for analysis.
While certain third-party analytics tools might suit your needs today, you’ll probably outgrow them as your analysis gets more complex. Additionally, you want something that will scale as you grow.
Whatever you choose, it should enable you to track page views and user actions (events) from both the client-side and server-side. Page views help you understand how users navigate around your application; events let you know what they click on and which actions they try to execute.
Client-side and server-side event tracking are necessary for two reasons:
Many users block client-side tracking. So, you may not see any events from them if you’re not triggering server-side events;
It is often useful to know how your server responds to certain requests — and that is more easily collected from the server side.
You could attempt to build this instrumentation infrastructure yourself. Or, you can go with something like Segment. At Jut, we elected to use Segment because their platform allows us to send user data to almost any tool imaginable. We’d also rather avoid reinventing the wheel.
2. You Can’t Foresee All The Questions You’ll Want To Ask
Once you choose a method for reporting user actions, you need to decide on which actions to report. The standard rule here is to track as much as possible. You never know which questions you will want to ask in the future. And since data storage is cheap, it’s better to have the data lying around than have to add instrumentation and wait for data to accumulate before you can use it.
It may seem like a lot of pointless work, but I’ve never regretted adding instrumentation. And it’s really not that much work in the grand scheme of things.
Even if you’re collecting all the right data, you’ll probably run into a scenario where you’ll ask a question that your analysis tool isn’t capable of answering. This happens more often than you would think.
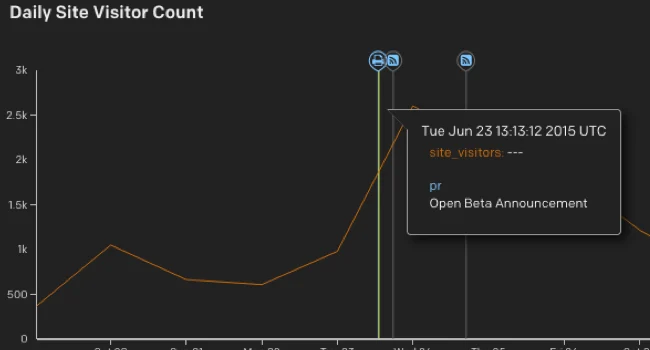
For example, Google Analytics can’t tell you who is doing what, and apps like Mixpanel can’t combine point-in-time events like product launches with daily metrics like signups on the same chart.
There are two ways around this: keep the raw data or use an analytics tool that doesn’t constrain you to a limited set of questions. The raw data allows you to answer these questions — but it also demands pretty technical skills that you might not have available. In contrast, a product that doesn’t impose any limitations ensures that you can handle every question that pops up.
3. Maintain Control of Your Data
It’s your data, so it should follow your rules. If you want to keep the data safe behind your firewall, you should be able to. If you don’t want to sample or roll up your data, you shouldn’t have to. Likewise, if you want to keep the data around forever, you should be able to. Google Analytics will sample your data once you reach a certain scale. This means you can’t trust the conversion rates that Google Analytics gives you.
Additionally, you will inevitably change the structure/schema of your data as your organization grows and your needs change. If you’re shipping your data off to third party tools, then these schema changes can cause problems. And schema changes in SQL, Redshift, or Hive are more trouble than they’re worth.
4. Keep the End Users of Your Data In Mind
Who in your company will want access to this data? You may have developers, technical-leaning analysts, and code-challenged managers who will want to see the data. Most likely, each person will want to ask different questions. They will also have varying capabilities for answering those questions.
You don’t want to build an analytics infrastructure that is only usable by your developers. This forces them to spend valuable time building applications on top of the data or constantly responding to manager requests to see the data in slightly different ways.
At the same time, you don’t want to use data analysis tools that severely limit the ways you can view your data. If you can’t answer a question because your analysis tool isn’t capable of doing something like a cohort report or regression analysis, then the time you spent building the infrastructure is as good as wasted.
5. What Else Can You Do with Your Data?
Data is not a one-trick-pony. You can really leverage the work you put into building an analytics infrastructure by finding other uses for your data…if your infrastructure allows you to.
It’s great to be able to analyze user data to learn what your users have done in the past — but you will be even more successful if you know what they’re doing right now.
For example, you can set up alerts to notify you when new users sign up for your product. If they run into problems afterward, fire events that trigger additional alerts so your customer success team can reach out and offer real-time assistance.
If your analytics tools offer REST APIs, your app can make use of the data in interesting ways. For example, you can build a customer support portal into your product using the data to make it easier to help customers. You could also surface usage data to your customers (for example: how does their usage compare to the average user?)
So, what’s next?
I’ve helped set up analytics infrastructures multiple times at multiple companies. So, I’ve gotten to experience all of these issues firsthand.
I am happy to say that the most recent analytics infrastructure I was involved with handles each of them in a graceful way that doesn’t limit us. You can do this too, and now you know what to watch out for.
This is a guest post by David Cook. If you are looking to be a great product manager or owner, create brilliant strategy, and build visual product roadmaps — start a free trial of Aha!
David Cook does growth marketing at Jut, where he analyzes user behavior across Jut’s website, product usage, and retention. As a data nerd, he gets a special kick out of helping shape Juttle — Jut’s data programming language for the modern needs of analytics. David also has a wide background in growth marketing technologies including SQL, Redshift, Hadoop, and Hive from time spent at Atlassian.