
From many to one: Moving our JavaScript code into a monorepo
Do we need a monorepo?
When I first joined Aha!, I was surprised by how well-structured the engineering onboarding program was. I spent several weeks getting to know all the teams and learning the pieces of our system. What I didn't realize at the time was these onboarding conversations gave me more than basic technical knowledge. They opened a door into the full development workflow. When I saw a simple style change in our web components library take two pull requests and half an hour, I knew there was an unusual pain point.
All of our products exist in a single Rails repository, so it's fair to say that we run a multiproduct monolith that shares business logic, pieces of UI, and more. This makes it easy and fast to work on new features no matter the product(s). In contrast, much of our JavaScript code used to exist as private npm packages. Although having private packages is great for reusing code in many places, it is not the best option if you are mostly using them in a single place — because it adds too much overhead to the process. In our case, we were pulling most of the packages only into our Rails monolith.
At Aha! we are interrupt driven, and the engineering team makes big efforts to create tools that help us do our work while being able to switch contexts easily and tackle bugs, assist a teammate, or just work on something else if we need to. The process to work on our private npm packages wasn't interrupt driven at all. If you had to work on one of our private packages, you knew it was going to take a significant amount of time (even if it was as simple as a style change in our web components library).
Even though it could get tedious, the manual process was pretty straightforward:
- Clone the repository of the package.
- Install the npm dependencies with the correct node version.
- Start the local development environment.
- Make changes to the codebase.
- Test changes in the package's local development environment.
- Link changes to our Rails app using yalc.
- Test changes in our local app environment.
- Repeat steps four through seven until you are happy with the changes.
- Create a pull request in the private package repository with the new changes.
- Request code review.
- Once code review is completed, merge the pull request and push the new package version to npm.
- Create a pull request in the Rails app to bump the package version.
- Request code review.
- Once code review is completed, merge the pull request and deploy to production.
The amount of time it took to ship anything related to a private npm package was way higher than what we were comfortable with, and having to request code reviews twice also took time from whoever was doing the reviews. During my first weeks, I only heard about this problem. But in my first few months at Aha!, I worked constantly in multiple private npm packages and quickly realized that this was really degrading the developer experience.
We need a monorepo — now what?
After experiencing this problem firsthand, I knew we had to do something about it. We don't have many meetings at Aha!, but we do have weekly check-ins with our managers. These are the perfect time to talk about what we would like to work on in the future. I volunteered to work on a monorepo proof of concept (POC) to determine whether or not it was feasible with our current architecture. We had a very specific set of goals for our monorepo:
- It needs to maintain Git history: Some of our packages are a couple years old, and we didn't want to lose all that history.
- It must be simple: We didn't want to add more complexity to an already complex codebase.
- It must improve developer experience: We didn't want to move the burden somewhere else — we were looking for a real solution.
- It must be compatible: We didn't want to make major changes to our tooling or CI.
Maintaining Git history
Code is a living creature, and keeping its history was one of the main problems we had to solve if we wanted to move forward with a monorepo. We knew we wanted to migrate our packages into a folder at the root of our Rails app named "packages." There are some options one can take to maintain Git history when moving code across repositories, but we went with a simple one: a combination of git mv and git merge --allow-unrelated-histories. The steps we followed to move repositories into our Rails app were pretty simple:
# At the root of the package repository
# Move all the code into packages/package-name so we can merge it into our rails app.
git mv -k * packages/[package-name]
git mv -k .* packages/[package-name]
# Commit and push changes
git add --all
git commit -m "package-name: prepare codebase for monorepo"
git push origin master
# At the root of our rails app
# Add the package remote to our rails app
git remote add [package-name] [package-name].git
git fetch [package-name]
# Merge the package repository into our rails app
git merge [package-name]/master --allow-unrelated-histories
# Remove package remote
git remote remove [package-name]
# Commit and push changes
git add --all
git commit -m "Add package-name to the monorepo"
git push origin master
With these simple commands, we were able to move packages code into our Rails app while maintaining Git history.
Keeping it simple
After figuring out Git history, we jumped into the next task — and the most important, If I'm honest — which is figuring out how to build a monorepo that doesn't add too much complexity to our codebase. If you search for information about JavaScript monorepos, you'll find something like this:

There are many great tools for managing a monorepo, but I'm only focusing on the ones that are purposely built with JavaScript and TypeScript in mind.
In short, you will see tools such as Lerna, Nx, Turborepo, and Rush.js. When you start reading their documentation, you realize that there are so many possible combinations because you can use them with npm, Yarn, or pnpm. This makes certain combinations more suitable than others depending on your project's configuration and needs.
We wanted to choose a tool that would allow us to grow for several years without worrying about major changes between releases. Additionally, we needed an easy-to-use interface. But it's hard to tell what tool is right for you if you don't try them all, right? We initially removed Lerna and Rush.js from the list of tools we wanted to try. The company that is behind Nx took over the stewardship of Lerna, so between Nx and Lerna, we just wanted to try Nx. Rush.js is a great tool with a lot of features, but it's designed to shine in monorepos with hundreds of packages — and that wasn't going to be the case for ours. We decided to do a POC assessing Nx and Turborepo because they share similar features that were compelling given what we wanted from our monorepo. These included:
- Local computation caching
- Local task orchestration
- Distributed computation caching
- Detection of affected projects/packages
- Workspace analysis
- Dependency graph visualization
We didn't want to use one of these tools if it wasn't necessary, and because of that, we also included pnpm workspaces in the POC. They don't have many of these features, but it was unclear to us at the time if our monorepo needed all that functionality. After conducting the POC, we had a better understanding of the pros and cons of each tool.
Nx + pnpm
The first tool we tried was Nx. Although it's a very powerful and extensible tool, it added unnecessary complexity to our codebase. We didn't want to add another layer that our engineers had to learn in order to do their work. The way you define tasks in Nx and the concept of targets are simple to understand, but unique to the tool itself. This makes it difficult when it comes time to move into something else after you make your choice. Even though it's extensible, having a plugin ecosystem means that you could use someone else's code or build a plugin yourself if you would like to customize the monorepo even further. The features and functionality were there, but it wasn't a plug-and-play situation. The learning curve was also a bit demanding due to all the Nx-specific configurations, making it harder for us to justify the time and resource investment.
pnpm workspaces
With a very high bar set by Nx, we tried pnpm workspaces. They work great, are easy to use, and you don't need to add anything to make them work. If you are looking for something that can be set up in a couple minutes, this would probably be one of your top choices. For our monorepo, however, it lacked basic features such as local computation caching and local task orchestration. This made it hard to justify its use because it wouldn't help us manage our monorepo locally or in CI. We didn't want to build custom tooling to manage our monorepo. And even though this was the most frictionless approach we could've taken, it wasn't the best option for a team of 40+ engineers.
Turborepo + pnpm
Lastly, we tried Turborepo. At this point we knew Nx had the features we wanted, but it was very opinionated and had a steep learning curve. We also knew that plain pnpm workspaces lacked the basic features that would save us time throughout our day-to-day tasks, but they were simple and easy to understand with only a few new concepts to learn. It was great to find out that Turborepo had all the features we liked from Nx — including local computation caching, local task orchestration, and the ability to detect affected projects/packages — while being only a bit more complex than plain pnpm workspaces. Having this simple additional layer that already had everything we wanted without a steep learning curve was a win-win situation.
No new things to learn
The POC was a great opportunity to try many things in a short period of time before committing to a tool. In the end, we chose Turborepo because it works well with our current build systems and it's extremely easy to use. From the developer experience point of view, it's pretty similar to what we were already doing. Before adopting the monorepo, if you wanted to start our front-end development server, you would run yarn start. Now with our monorepo, you run pnpm start and that's it. If you are an engineer who is not actively making changes to the monorepo packages or configuration, you don't need to know anything else to use it. And if you want to use some of the more advanced Turborepo features, you can check their docs and append the flags to the command.
Again, it was paramount to our team to choose a tool that was as frictionless as possible. We love Rails. When adding new things, we usually try to follow the convention over configuration principle — and this wasn't any different with our monorepo.
Turborepo is configured with a single JSON file named turbo.json where you define all your pipelines in a simple way, like this:
{
"$schema": "https://turbo.build/schema.json",
"pipeline": {
"build": {
"cache": true,
"outputs": ["dist/**"],
// "A workspace's `build` command depends on its dependencies'
// or devDependencies' `build` command being completed first"
"dependsOn": ["^build"]
},
"start": {
// "A workspace's `start` command is a long-running process
"persistent": true
"dependsOn": ["^build"]
},
"test": {
// "A workspace's `test` command depends on its own `lint` and
// `build` commands first being completed"
"dependsOn": ["lint", "build"]
},
"deploy": {
// "A workspace's `deploy` command, depends on its own `build`
// and `test` commands first being completed"
"dependsOn": ["build", "test"]
},
// A workspace's `lint` command has no dependencies
"lint": {}
}
}
The name of each pipeline is the name of the pnpm script that will run on each package (respecting the order defined by the dependency graph). There are many options for configuring this file, but dependsOn, outputs, cache, and persistent are among the most relevant.
dependsOn: The list of tasks this task depends onoutputs: The set of glob patterns on a task's cacheable file system outputscache: Whether or not to cache the taskoutputspersistent: A task can be labeled as persistent if it is a long-running process, such as a dev server or --watch mode
We only have to worry about configuring the file. The dependency graph is autogenerated, so we don't need to tell Turborepo what depends on what and so on. A simple dependency graph could look like this:
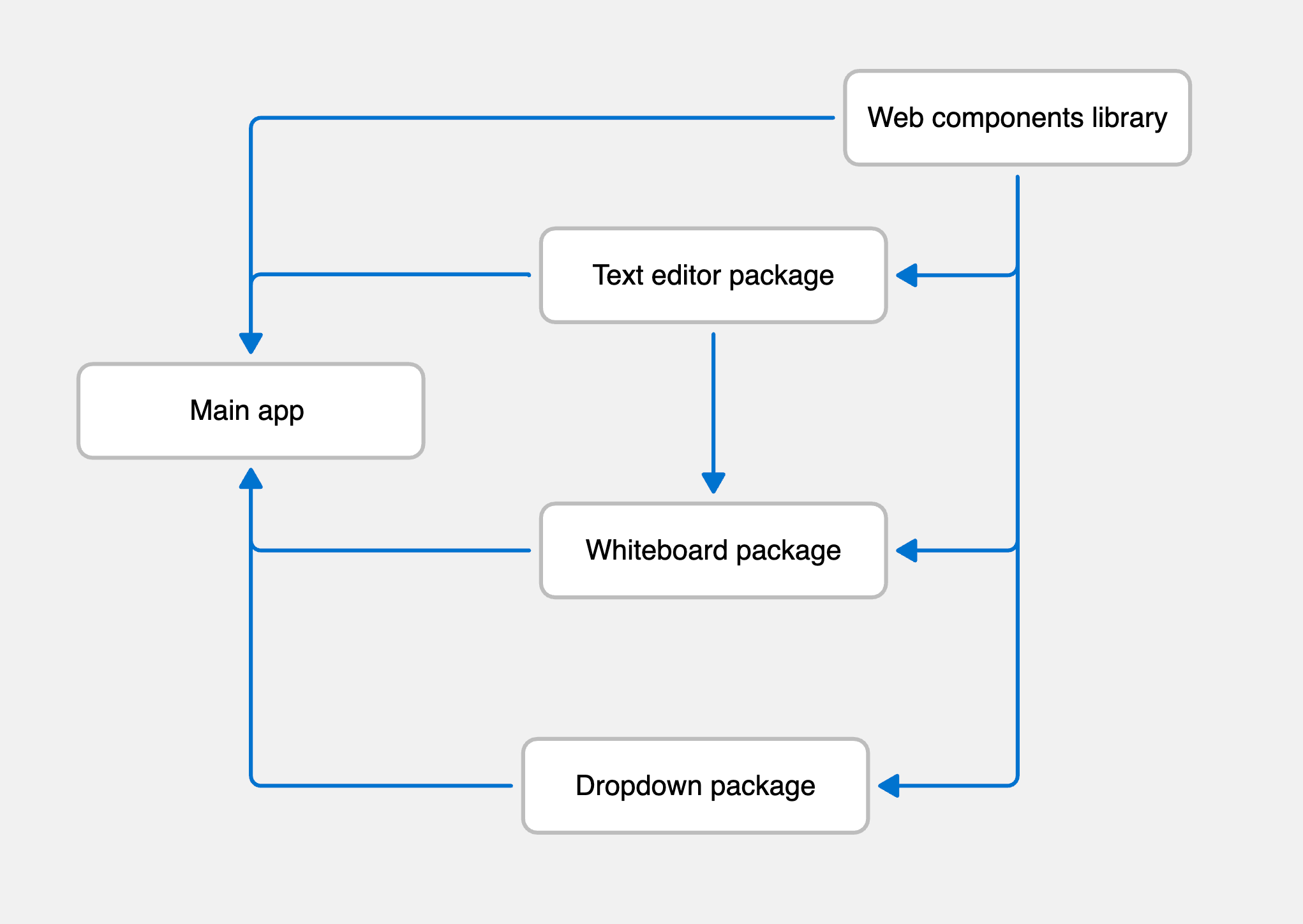
If we take the turbo.json file from above and this dependency graph as an example, Turborepo will do the following every time we run the start pipeline:
- Build the web components library
- Build the text editor package
- Build the whiteboard package
- Build the dropdown package
- Start the watch server for all these packages
- Start the watch server for the main app
Turborepo makes it pretty easy to understand what's going on, and there are no new concepts to learn nor complex ideas to think about. Not everyone on the team needs to understand how this works under the hood in order to use it. But if anyone would like to make changes to the monorepo, it wouldn't be a complex task — because it's simple to work around Turborepo and its concepts.
It just works!
I joined Aha! in January 2022, and we shipped our monorepo at the beginning of Q3 in 2023. Ever since, it has been working without issues both in production and in the local environments for everyone on the team. We had to make some changes to our CI and build systems, but those were minimal. And in most cases, it ended up simplifying the code we were running in the past. We don't use all the features that Turborepo offers, but we use what we need — which is great. Being able to use the tool in the way you want (and not having to do so in the way the tool mandates) is something that makes us really happy about our choice.
Since we adopted the monorepo, we have pushed close to 2,500 commits that include changes to our packages in almost 450 pull requests. At the beginning of this blog, I was talking about how our old process to ship changes from our private packages was slow even for very small things. If we are conservative, we could say that every pull request took us an average of 30 more minutes before the monorepo. So we have saved close to 55 hours worth of development time — or more accurately, of waiting in front of the screen — each month.
In the end, it is not only about the time we save, but more about the frustration we remove from our day-to-day work. Having one less thing to worry about frees up more space in our heads to think about what really matters: shipping awesome features for our customers.


